Kubernetes 的基本概念
设计理念
用户定义应用程序的规格,Kubernetes 负责按照定义的规格部署并运行应用程序。
Kubernetes 特点
- 可移植: 支持公有云,私有云,混合云,多重云
- 可扩展: 模块化, 插件化, 可挂载
- 自动化: 自动部署,自动重启,自动伸缩
Pod

Pod基本特性
Pod是由一个或多个业务紧耦合的容器组成的容器组合,目前支持Docker容器技术,CoreOS的rkt等容器技术,并很容易扩展支持更多容器技术。
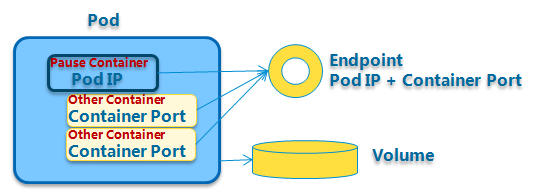
每个Pod都有一个被称为根容器的特殊容器:Pause容器,它对应的镜像属于Kubernetes平台的一部分。
为什么Kubernetes会设计出一个根容器?
原因之一:在一组容器作为一个单元的情况下,我们很难对整体简单地进行判断并有效地采取行动。比如一个容器死亡了,此时算是整体死亡吗?是N/M的死亡率吗? 引入业务无关且不容易死亡的Pause容器,以它的状态代表整个容器的状态,就简单、巧妙地解决了这个难题。
原因之二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂架的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。
Pod中的所用容器会被一致调度、同节点部署,并且在一个共享环境中运行。这里的共享环境包括以下几点:
所有容器共享一个IP地址,即
Pause容器的IP地址,以及端口空间,意味着容器之间可以通过localhost高效访问,不能有端口冲突允许容器之间共享存储卷,即
Pause容器挂接的Volume,通过文件系统交互信息容器之间可以通过IPC(inter-processcommunication)进行通信
Pod有两种类型:普通Pod和Static Pod,后者比较特殊,它的信息并不保存在etcd中,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。 而普通Pod一旦被创建,其信息会被放到etcd中存储,随后被Kubernetes Master调度到摸个具体的Node上并被绑定,随后该Pod被对应的Node上kubelet进程实例化成一组相关的Docker容器并启动起来。
从生命周期来说,Pod应该是短暂的而不是长久的应用。 Pods被调度到节点,保持在这个节点上直到被销毁。当节点死亡时,分配到这个节点的Pods将会被删掉。在实际使用时,我们一般不直接创建Pods, 我们通过replication controller来负责Pods的创建,复制,监控和销毁。
Pod应用场景
Pod的主要目的还是支持需要一起部署、一起管理的进程,包括:
内容管理系统,文件和数据加载进程,本地cache管理进程等
日志压缩、备份、快照等
数据变化监听、日志和监控适配器,事件分发等
控制、管理、配置、升级程序
实际的使用场景:
业务服务需要收集日志
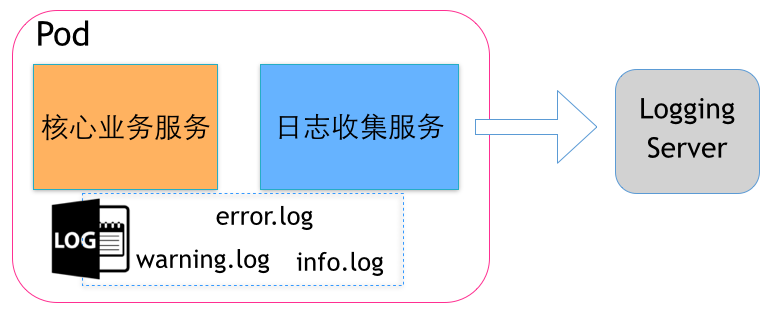
某服务模块已经实现了一些核心的业务逻辑,并且稳定运行了一段时间,日志记录在了某个目录下,按照不同级别分别为 error.log、warning.log、info.log,现在希望收集这些日志并发送到统一的日志处理服务器上。
这时我们可以修改原来的服务模块,在其中添加日志收集、发送的服务,但这样可能会影响原来服务的配置、部署方式,从而带来不必要的问题和成本,也会增加业务逻辑和基础服务的藕合度。
如果使用Pod的方式,通过简单的编排,既可以保持原有服务逻辑、部署方式不变,又可以增加新的日志收集服务。
而且如果我们对所有服务的日志生成有一个统一的标准,或者仅对日志收集服务稍加修改,就可以将日志收集服务和其他服务进行Pod编排,提供统一、标准的日志收集方式。
这里的核心业务服务、日志收集服务分别是一个Docker镜像,运行在隔离的容器环境中。
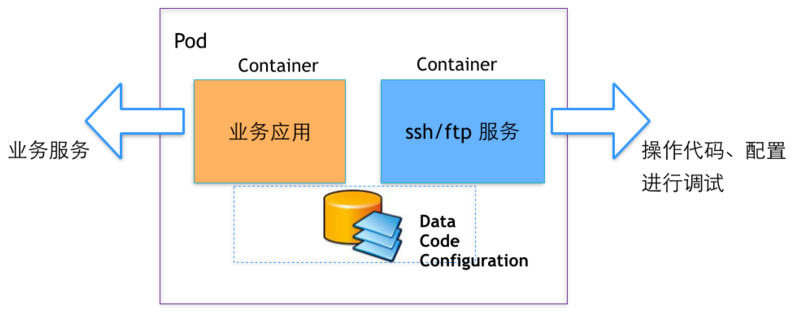
提供ssh、ftp访问容器数据的能力
Docker Hub或者很多第三方的镜像并没有安装sshd的服务,不方便我们进入容器进行配置、代码的修改、调试,很多时候需要重新构建镜像、或者在镜像基础上安装sshd的服务,这都需要时间和一定的学习成本。
而通过Pod的方式,我们就可以将现有镜像和一个ssh、ftp镜像进行编排,获得操作容器内数据的能力。
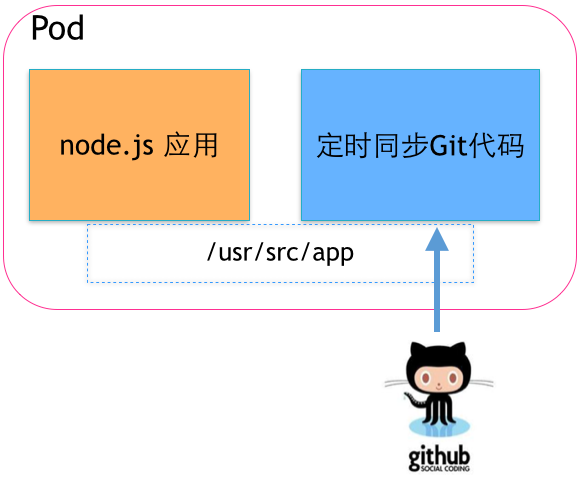
代码自动更新
我们部署了一个node.js的应用,而且部署了几十、上百个节点,那么我希望这个应用可以定时的同步最新的代码,以便自动升级线上环境。
这时,我们当然也不希望改动原来的node.js 应用,可以开发一个Git代码仓库的自动同步服务,然后通过Pod的方式进行编排,并共享代码目录,就可以达到更新node.js应用代码的效果。
并且这个同步服务还可以同其他使用Git代码仓库的服务编排,实现同样的需求。
适配不同IaaS平台的环境
我们开发一个节点管理的agent,这个agent需要读取当前部署环境的一些信息,可以通过底层平台的API实现。
但是,当部署到AWS、阿里云、青云等不同平台时,API就无法统一了。这样,我们可以实现不同平台的适配服务来获取各自的信息,并且和agent通过Pod编排部署,在不改变agent逻辑的情况下,通过服务组合来适配于不同平台。
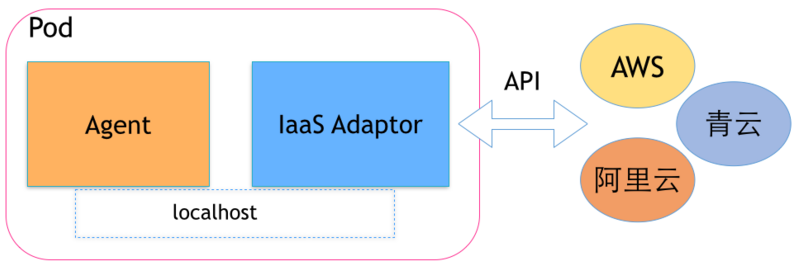
其实,Kubernetes 的一些新的功能需求,也会建议先通过Pod的编排来解决,而不是直接修改Kubernetes的代码,可见Pod还是用处多多的。
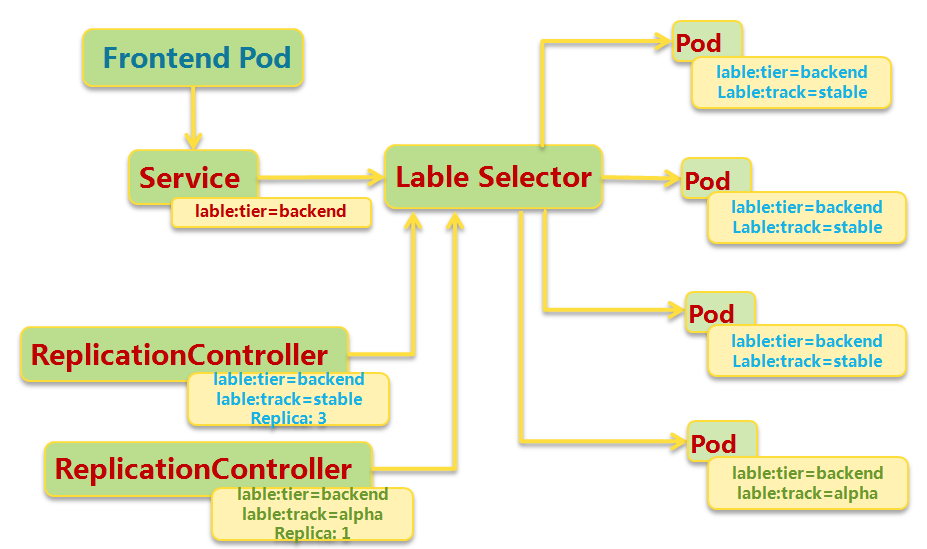
Replication controller
复制控制器确保Pod的一定数量的份数(replica)在运行。如果超过这个数量,控制器会杀死一些,如果少了,控制器会启动一些。控制器也会在节点失效、维护的时候来保证这个数量。所以强烈建议即使我们的份数是1,也要使用复制控制器,而不是直接创建Pod。
它其实定义了一个期望场景,即声明某种Pod的副本数在任意时刻都符合某个预期,所以RC的定义包含了如下几个部分:
Pod期待的副本数(replica)
用于筛选目标Pod的Label Selector
当Pod副本数量小于预期值的时候,用于创建新Pod的模板(template)
由于Replication controller无法准确表达它的本意,在kubernetes 1.2的时候,它升级为一个新的概念:replica set,与RC当前存在的唯一区别是,replica set支持基于集合的Label selector,而RC只支持基于等式的Label selector。
在生命周期上讲,复制控制器自己不会终止,但是跨度不会比Service强。Service能够横跨多个复制控制器管理的Pods。而且在一个Service的生命周期内,复制控制器能被删除和创建。Service和客户端程序是不知道复制控制器的存在的。
复制控制器创建的Pods应该是可以互相替换的和语义上相同的,这个对无状态服务特别合适。
Pod是临时性的对象,被创建和销毁,而且不会恢复。复制器动态地创建和销毁Pod。虽然Pod会分配到IP地址,但是这个IP地址都不是持久的。
Service
Service定义了一个Pod的逻辑集合和一个服务的入口访问地址。
集合是通过定义Service时提供的Label Selector完成的。举个例子,我们假定有3个Pod来处理后端业务。这些后端备份逻辑上是相同的,前端不关心哪个后端在给它提供服务。虽然组成这个后端的实际Pod可能变化,前端客户端不会意识到这个变化,也不会跟踪后端。
Service就是用来实现这种分离的抽象。
当在Master节点上创建Service时,Kubernetes会给它分配一个地址,这个地址即Cluster IP,假定为10.0.0.1,此地址从service-cluster-ip-range参数指定的地址池中分配,比如–service-cluster-ip-range=10.0.0.0/16。 假设这个Service的端口是1234。集群内的所有node节点上的kube-proxy都会注意到这个Service。 当kube-proxy发现一个新的service后,它会在本地节点打开一个任意端口,建立相应的iptables规则,重定向Cluster IP和port到这个新建的端口,开始接受到达这个服务的连接。
当一个客户端访问这个service时,这些iptable规则就开始起作用,客户端的流量被重定向到kube-proxy为这个service打开的端口上,kube-proxy随机选择一个后端Pod来服务客户。这个流程如下图所示:
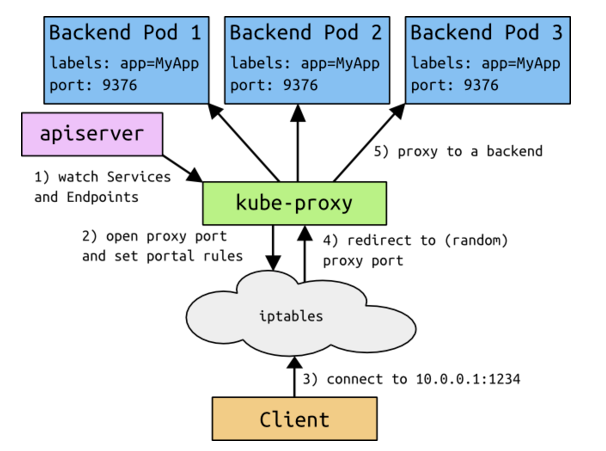
在kubernetes集群内,Node IP、Pod IP、Cluster IP 之间的通信,采用的是kubernetes自己设计的一种特殊的路由规则,与我们熟悉的IP路由有很大不同。
对于每个service,我们通常需要配置一个负载均衡实例来转发到对应的Node上,这的确增加了工作量以及出错率,于是kubernetes提供了自动化的解决方案,如果我们的集群运行在google的GCE公有云上,那么我们只要把service的type=NodePort修改为type=LoadBalance,此时kubernetes会自动创建一个对应的LoadBalance实例并返回它的IP地址供外部客户端使用。
文档信息
- 本文作者:Yu Peng
- 本文链接:https://www.y2p.cc/2017/03/28/kubernetes-concept/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)