Awesome
Awesome Distributed Deep Learning
GPU 共享
方案评估点
- 不会使用超过被分配的算力、显存大小
- 隔离本身不应该对于 GPU 算力有过多损耗
- 多个进程同时共享的时候,避免进程之间的干扰。
NVIDIA GPU 共享方案
GPU 的算力很强,GPU 硬件很贵,为了节省固定资产的投入,需要将多个推理服务部署在同一张 GPU 卡上,在保证服务质量的前提下通过 GPU 共享来提升 GPU 的利用率。目前英伟达官方的 GPU 共享技术主要有三种方案:
- NVIDIA MIG 方案
- NVIDIA vGPU 方案
- NVIDIA MPS 方案
NVIDIA MIG 方案
VIDIA MIG 方案,多实例 GPU (MIG) 扩展了每个 NVIDIA H100、A100 及 A30 Tensor Core GPU 的性能和价值。MIG 可将 GPU 划分为多达七个实例,每个实例均完全独立于各自的高带宽显存、缓存和计算核心。如此一来,管理员便能支持所有大小的工作负载,且服务质量 (QoS) 稳定可靠,让每位用户都能享用加速计算资源。
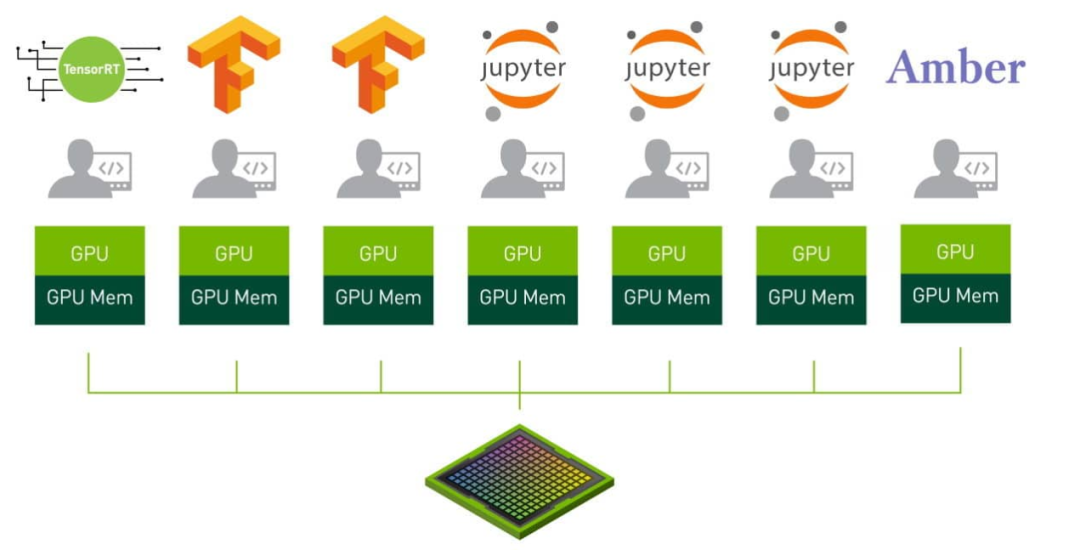
MIG,即是一种 Hardware Partition。硬件资源隔离、故障隔离都是硬件实现的 —— 这是无可争议的隔离性最好的方案。它的问题是不灵活: 只有高端 GPU 支持;只支持 CUDA 计算;只支持 7 个 MIG 实例。
NVIDIA vGPU 方案
NVIDIA vGPU 方案采用虚拟化的技术,基于 SR-IOV 进行 GPU 设备虚拟化管理,在驱动层提供了时间分片执行的逻辑,并做了一定的显存隔离,这样在对显卡进行初始化设置的时候就可以根据需求将显卡进行划分。其中时间分片调度的逻辑可以是按实例均分,或者是自定义比例,显卡的显存需要按照预设的比例进行划分。
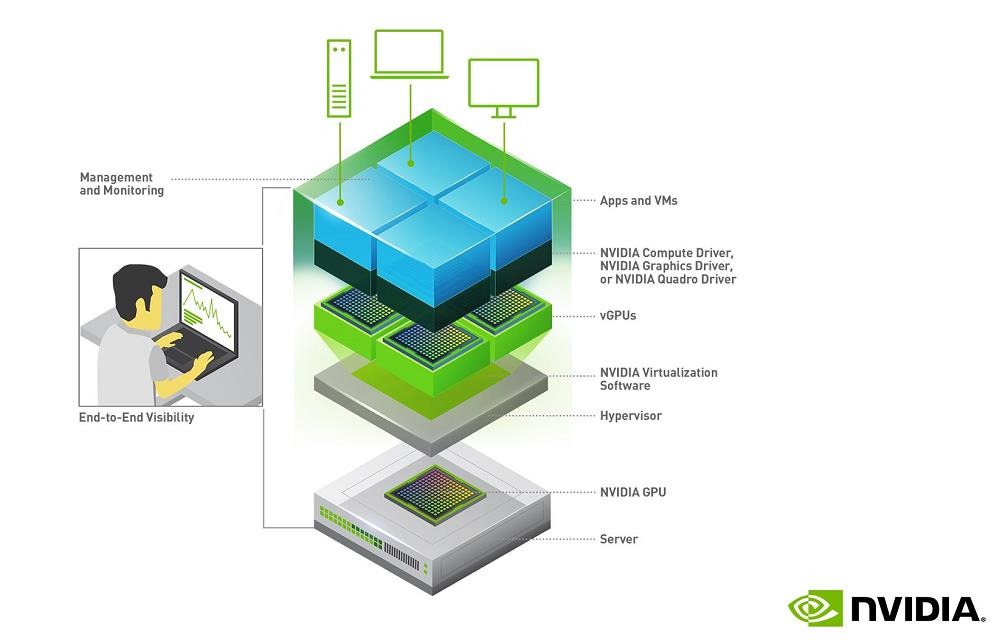
Nvdia的vGPU方案在实施中有下面两点限制:
- vGPU划分完成之后,如果要改变这种预定义的划分,需要重启显卡才能生效,无法做到不重启更改配置。
- 其方案基于虚机,需要先对 GPU 物理机进行虚拟化之后,再在虚拟机内部署容器,无法直接基于物理机进行容器化的调度,另外 vGPU 方案需要收取 license 费用,增加了使用成本。
NVIDIA MPS 方案
NVIDIA MPS 方案是一种算力分割的软件虚拟化方案。它通过将多个进程的 CUDA Context,合并到一个 CUDA Context 中,省去了 Context Switch 的开销,也在 Context 内部实现了算力隔离。如前所述,MPS 的致命缺陷,是 把许多进程的 CUDA Context 合并成一个,从而导致了额外的故障传播。所以尽管它的算力隔离效果极好,但长期以来工业界使用不多,多租户场景尤其如此。
寒武纪 GPU 共享方案
寒武纪 SR-IOV 方案
SR-IOV 是 PCI-SIG 在 2007 年推出的规范,目的就是 PCIe 设备的虚拟化。SR-IOV 的本质是什么?考虑我们说过的 2 种资源和 2 种能力,来看看一个 VF 有什么:
- 配置空间是虚拟的(特权资源)
- MMIO 是物理的
- 中断和 DMA,因为 VF 有自己的 PCIe 协议层的标识(Routing ID,就是 BDF),从而拥有独立的地址空间。
那么,什么设备适合实现 SR-IOV?其实无非是要满足两点:
- 硬件资源要容易 partition
- 无状态(至少要接近无状态)
常见 PCIe 设备中,最适合 SR-IOV 的就是网卡了: 一或多对 TX/RX queue + 一或多个中断,结合上一个 Routing ID,就可以抽象为一个 VF。而且它是近乎无状态的。
试考虑 NVMe 设备,它的资源也很容易 partition,但是它有存储数据,因此在实现 SR-IOV 方面,就会有更多的顾虑。
回到 GPU 虚拟化:为什么 2007 年就出现 SR-IOV 规范、直到 2015 业界才出现第一个「表面上的」SRIOV-capable GPU ?这是因为,虽然 GPU 基本也是无状态的,但是它的硬件复杂度极高,远远超出 NIC、NVMe 这些,导致硬件资源的 partition 很难实现。
寒武纪虚拟化技术——vMLU,该虚拟化技术允许多个操作系统和应用程序共存于一个物理计算平台上,共享同一个芯片的计算资源。它为用户提供良好的安全性和隔离性,还支持如热迁移等高灵活特性。vMLU 帮助提高云计算密度,也使数据中心的 IT 资产管理更灵活。
除了虚拟化基本的资源共享特性,思元 270 首推的 SR-IOV 虚拟化技术,支持运行在云服务器上的多个实例直接共享智能芯片的硬件资源。传统虚拟化系统中大量的资源和时间损耗在 Hypervisor 或 VMM 软件层面,PCIe 设备的性能优势无法彻底发挥。而 SR-IOV 的价值在于消除这一软件瓶颈,助力多个虚拟机实现高效物理资源共享。
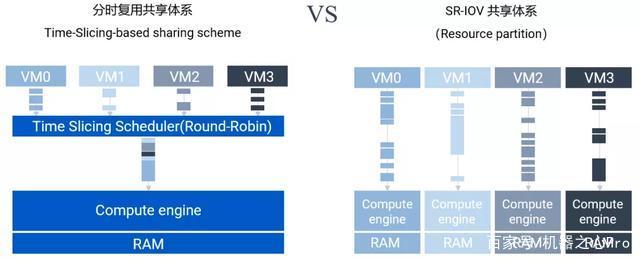
与传统图形加速卡的 vGPU 所采用的虚拟化技术不同,思元 270 采用「非基于时间片的共享」方式,因为其没有因时间片切换上下文带来的性能损失,能充分保证各 VF 独立的服务质量,彼此完全独立运行互不影响。
另外,SR-IOV 还可以避免因分时复用切换应用带来的性能开销。vMLU 搭配 Docker 或 VM 运行时,单个 VF 业务性能保持在硬件性能的 91% 以上。这使得用户在多模型并行时,对各 VF 可以做出更准确的服务质量 (QoS) 预期,而不必考虑多模型时的拥塞或切换带来的性能开销。
基于 SR-IOV 的 vMLU:更好的租户隔离性
虚拟化技术被数据中心广泛采用,除了因为其提供了对资源共享的能力(提供了更好的密度性能),也因为相对于其它技术 (如 docker), 虚拟化提供了更好的隔离性和安全性。寒武纪 vMLU 基于 SR-IOV 的虚拟化技术可以帮助云用户实现更好的隔离特性,具体优势如下:
- 资源独立,互不干扰,能确保服务质量(QoS);
- 多任务时,没有无队列阻塞的烦恼;
- 其具备独立内存资源,各 VF 之间互不可见;
- 它的部署相对简单,不需要对开源软件成分进行修改。
截获 CUDA API 实现显存及算力隔离
显存隔离
对于深度学习应用来说,对于显存的需求来自于三个方面。
第一是模型的 CUDA kernel context,可类比于 CPU 程序中的 text 段,提供给 CUDA kernel 执行的环境,这是一项刚需,没有充足的显存,kernel 将无法启动,且 context 的大小随着 kernel 的复杂程度有增长,但在整体模型显存需求中是最小的一部分。
第二部分来自于模型训练得出的一些参数,如卷积中的 weight 和 bias。
第三部分来自于模型在推理过程中的临时存储,用于储存中间的计算结果。
对于一般的模型来说,基本都不需要占用整个GPU的显存。但是这里有一个例外,Tensorflow 框架默认分配所有 GPU 的显存来进行自己的显存管理。当然 Tensorflow 框架有相应的选项可以屏蔽该行为,但是对于平台来说,要让每个用户修改 TF 的配置为屏蔽该行为,就不太可行。
为应对这一问题,一个巧妙的方法可以在不需要应用开发者参与的情况下,让 Tensorflow 的部署应用只分配它所需的显存大小而不出现问题。该方法即 API 动态拦截。Tensorflow 之所以可以知道当前 GPU 的剩余显存,是通过 cuDeviceTotalMem/cuMemGetInfo 这两个 CUDA library API。通过 LD_PRELOAD 的方式,在钩子 so 中实现这两个 API,那么 Tensorflow 执行的时候,link 首先会调用的是的 API 实现,而不是 CUDA 的,这样就可以动态的修改这两个 API 的返回结果,如这里想做的,将特定 Tensorflow 应用的显存配额限制在其申请数值。
在系统实现的过程中,还对 cuMemAlloc/cuMemFree 做了同样的拦截,目的是为了能够对同容器中的多个 GPU 进程进程统一管理。当多个 GPU 进程分配显存之和超过其配额时,可以通过 cuMalloc 来返回显存不足的错误。容器内显存配额管理是通过 share mem 来做的。
相关实现方式可以参考:vcuMemGetInfo
算力隔离
GPU程序的执行,是通过kernel的片段来具体实施,在CPU侧launch了 kernel之后,具体的kernel及其调用参数随即交由GPU的硬件调度器来在某个未来的时间点真正运行起来。在默认的情况下,kernel是被派发给GPU上所有的SM,且执行过程中不能被中断。
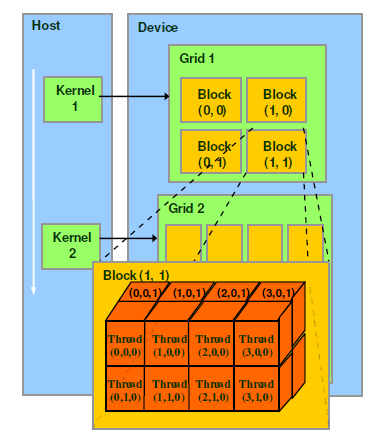
CUDA中用来区分thread,来判断代码应该处理数据的偏移量的方法,是通过CUDA中的blockIdx/threadIdx这两个内嵌变量。这两个变量在机器码上是只读的,在thread由硬件调度器派发的时候所指定。通过硬件调度器,就完成了抽象的blockIdx/threadIdx和具体的SM/SP的绑定。
为了能够精确的控制算力,我们就不能再依赖硬件调度器来控制内核启动。在这里用了一个取巧的方法,就是让内核启动之后被“困”在固定数目的SM上面,这个数目的值和GPU整体SM个数的比例就是给这个内核算力配比。
为了形象化来阐述思路,这里我们对GPU做了一个抽象化的改动,SM的个数被定义为10个。然后有一个启动参数为«<15,1»>的内核,即CUDA block size为15,thread size为1。它正常启动的时候,硬件调度器会给每一个SM上分配一个内核的副本。这样在第一时间就消耗了10个block的副本,随后每个SM上内核执行完毕之后会退出,硬件调度器会进一步分配剩下的5个block副本,在这个也执行完毕之后就完成了整个内核的执行。
算力切分之后,我们会在内核启动时,动态的修改其启动参数,将其CUDA block size从15变为5。这样硬件调度器就会将内核副本分配到GPU上一半数目的SM上,空闲的一半可以为其他内核所使用。
我们虽然通过动态修改启动参数的方法,避免了内核占满全部SM资源,但此时还没完成“困”这一动作。所以此时的内核行为是其完成预定逻辑之后,会退出,导致此时内核不能覆盖block size为15时的数据空间。为了将其“困“住,我们在内核的汇编EXIT处,替换成了BRANCH操作。这样内核完成本身的逻辑之后,会跳转到我们预设的一段逻辑中。这个逻辑完成虚拟blockIdx/threadIdx的自增操作,随后再跳转到内核开始位置,来基于更新的blockIdx/threadIdx来进行新一轮计算。
这次需要指出的是blockIdx/threadIdx为只读寄存器,所以没办法直接更改它的值。作为一个替代的解决方案时,将内核中的blockIdx/threadIdx进行整体替换为可写的寄存器,这样我们就可以在预设的跳转逻辑中做更改操作。
参考资料
文档信息
- 本文作者:Yu Peng
- 本文链接:https://www.y2p.cc/2021/10/10/gpu/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)